使用 OVS DPDK 前用户需要手动为其分配大页内存,但是分配多少大页内存合适呢?这没有一个简单通用的解答,OVS DPDK 需要的大页内存数依赖于许多东西,例如 ports MTU 的大小,ports 所在的 NUMA node。要准确回答这个问题,就要搞清楚 OVS DPDK 是如何使用这些内存的。
内存的用途
这些大页内存是用来做什么的呢?
这些大页内存主要是用来做 buffer 的,每个 buffer 代表了 OVS DPDK 中的一个 packet。在 OVS DPDK 启动时会用大页内存分配一组或者多组 buffers,每组 buffer 大小相同,并且以环的结构存储,这样的一组 buffer 就叫 memepool。每当 OVS DPDK 收到一个 packet,就会用一个 buffer 来保存它。OVS DPDK port 可以是类型为dpdk的物理网卡,或者dpdkvhostuser,或者dpdkvhostuserclient的虚拟网卡。
为什么要用大页内存?
Linux 系统内存分页大小默认为 4K bytes,MTU 默认为 1500 bytes,再考虑到每个 buffer 中还要保存一些元数据,那么这个 buffer 大小很容易达到分页大小,为了 localty 以及性能的考虑,就需要使用大页内存。
DPDK 设备内存模型
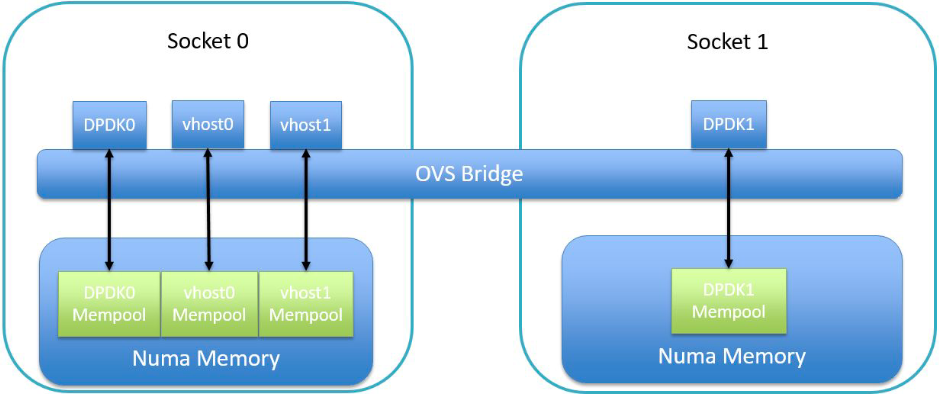
mempool 可以被一个单独的 port 占用,也可以在多个 port 中共享。由此分为两种 DPDK 内存分配模式:shared memory和pre port memory。
shared memory
OVS DPDK 默认使用shared memory模型。在这种情况下,多个 port 可以使用同一个 mempool。当添加一个 port 到 OVS DPDK 时,它会分配到对应的 MTU 和 socket ID,如果此时已经有了一个 mempool,且该 mempool 早已被分配给了一个拥有相同 MTU 和 socket ID 的 port 时,这个 mempool 就会被两个 port 共享。如果没有满足要求的 mempool,就会新建一个。
在这里可以看出 mempool 和 MTU 有很大的关系,如果几个 port 使用的 MTU 不同,那么它们就无法分享 mempool,也就意味着要分配多个 mempool,需要更多的大页内存。
注意:实际上并不要求 MTU 完全一致,只需要对应的 Buffer size 相同即可。
优点:
- 成熟的解决方案
- 内存占用少
- buffer 的配置考虑到了执行中最糟糕的情况
缺点:
- 可能会耗尽其他设备的内存
pre port memory
pre port memory从字面意思就可以知道,在这种模型下,每个 port 拥有自己的 mempool。这种模型的好处显而易见,不共享内存,自己的 mempool 就不会被其他的 DPDK 设备消耗掉。缺点也很明显,就是很费内存。在使用这个模型之前,用户需要了解其部署的内存需求,并分配所需的大页内存。
要开启pre port memory支持需要在启动 OVS DPDK 之前手动设置:
1 | |
优点:
- 一个更加透明的内存使用模型
- 不会因为竞争而耗尽内存
缺点:
- 内存占用现在受到:
- rx/tx 队列数的影响
- rx/tx 队列大小的影响
- PMD 数量的影响
- 在不同的 OVS 版本上,所需 1 的内存大小会不同。
计算内存需求
需要的大页内存的计算公式大致如下:
\[RequiredMem = bufferSize * mempoolSize\]但是这里有几个需要注意的地方:
- 每个 mempool 中 buffer 的多少在不通的 DPDK 内存模型下是不一样的;
- buffer 的大小受 MTU 大小的影响;
由于对齐和舍入的原因,通常 buffer 大小要比 MTU 大很多。
Shared memory 内存计算
mempool size
在share memory模型下,mempool 中 buffer 数量受 MTU 影响如下表所示:
| MTU Size | Num Buffers |
|---|---|
| 1500 or greater | 262144(256K) |
| Less than 1500 | 16384(16K) |
如果没有足够的内存提供 262144 的 buffer,则会对半砍,直到 16384。
buffer size
buffer 大小除了 MTU 之外,还受到其他 OVS 数据包类型的元数据集成和对齐舍入的影响,这部份大小在 OVS 代码中都计算好了。因此,实际的 buffer 大小要比 MTU 大,根据实际情况的不同,大概每个 buffer 会多 1000~2000 bytes。举例来说:
| MTU Size | Buffer size |
|---|---|
| 1500 | 3008 |
| 1800 | 3008 |
| 6000 | 7104 |
| 9000 | 10176 |
举个🌰:
1 | |
NUMA 的影响
前面提到,要共享 mempool,除了 buffer size 之外,还要考虑 socket,这是出于性能考虑,OVS DPDK 只会使用和对应 port 关联的 NUMA node 上的内存。例如,一个物理 dpdk port 在 NUMA0 上,那么对应的,它接收到的 packet 就会使用 NUMA0 上的内存。也就是说,即便 buffer size 一样,但是不在同一个 numa node 上,也无法共享 mempool。
注意:这里的 socket 指的是 cpu 的插槽,通常来说,同一个 socket 下的 cpu 在一个 numa node 上,某些架构比较特别的国产 cpu 则不同。
举个🌰:
1 | |
因此在分配大页内存时,最好的实践方法是在所有 node 上都分配 mempool。
1 | |

pre port memory 内存计算
pre port memory模型的内存计算更加复杂,需要考虑到 datapath 和设备配置等多个动态因素。
对一个 port 需要的 buffer 数量的估算方法如下:
1 | |
在 OVS 中使用的算法如下:
1 | |
- requested number of rxqs:设备申请的 rx 队列数;
- requested rxq size:每个 rx 队列所需的描述符数量;
- requested number of txqs:设备申请的 tx 队列数,通常为 PMD 数 +1;
- requested txq size:每个 tx 队列所需的描述符数量;
- min(RTE_MAX_LCORE, requested number of rxqs):取 DPDK 最大可支持的 lcore 和设备 rx 队列数的较小值;
- netdev_max_burst:一次 burst 的最大 packet 数量,默认为 32;
- MIN_NB_MBUF:为其他 case 预留的内存,默认为 16384。
Reference
Open vSwitch-DPDK: How Much Hugepage Memory?